Gordon Shotwell
Blog
About
Presentations
Technical Debt is a Social Problem
Building secure systems
Blog
Categories
All
(12)
Covid
(3)
Data Science
(9)
Economics
(1)
Education
(2)
Personal
(1)
R
(2)
Vitamin D
(1)
philosophy
(1)
Canada’s untapped talent: the remote hiring opportunity you’re missing
Economics
My first data job was as a data scientist at a clinical trial company in Halifax in 2015. I didn’t love the job and when I started looking for my next role, I discovered a…
Nov 10, 2023
Gordon Shotwell
Large language models will never be conscious
Data Science
philosophy
Many engineers who work in deep learning are worried about machines gaining consciousness. Over the last ten years there’s been an explosion in tools which use deep learning…
Aug 10, 2022
Gordon Shotwell
Testing dbplyr packages
R
Data Science
Data science students are often told that SQL is the most important tool to learn. This advice makes some sense given how ubiquitous SQL is in industry, but I think it’s a…
Aug 4, 2022
Gordon Shotwell
What MS taught me about the pandemic
Covid
Personal
I was diagnosed with multiple sclerosis about seven years ago. My first symptoms were numbness in my feet which I thought were caused by tight shoes, but by the time I was…
Jan 11, 2022
R package build
What’s the blockchain good for anyway?
People have invested about $3 trillion in blockchain technologies globally, but it’s still pretty hard to understand the value that is being produced by this technology. Can…
Dec 2, 2021
Gordon Shotwell
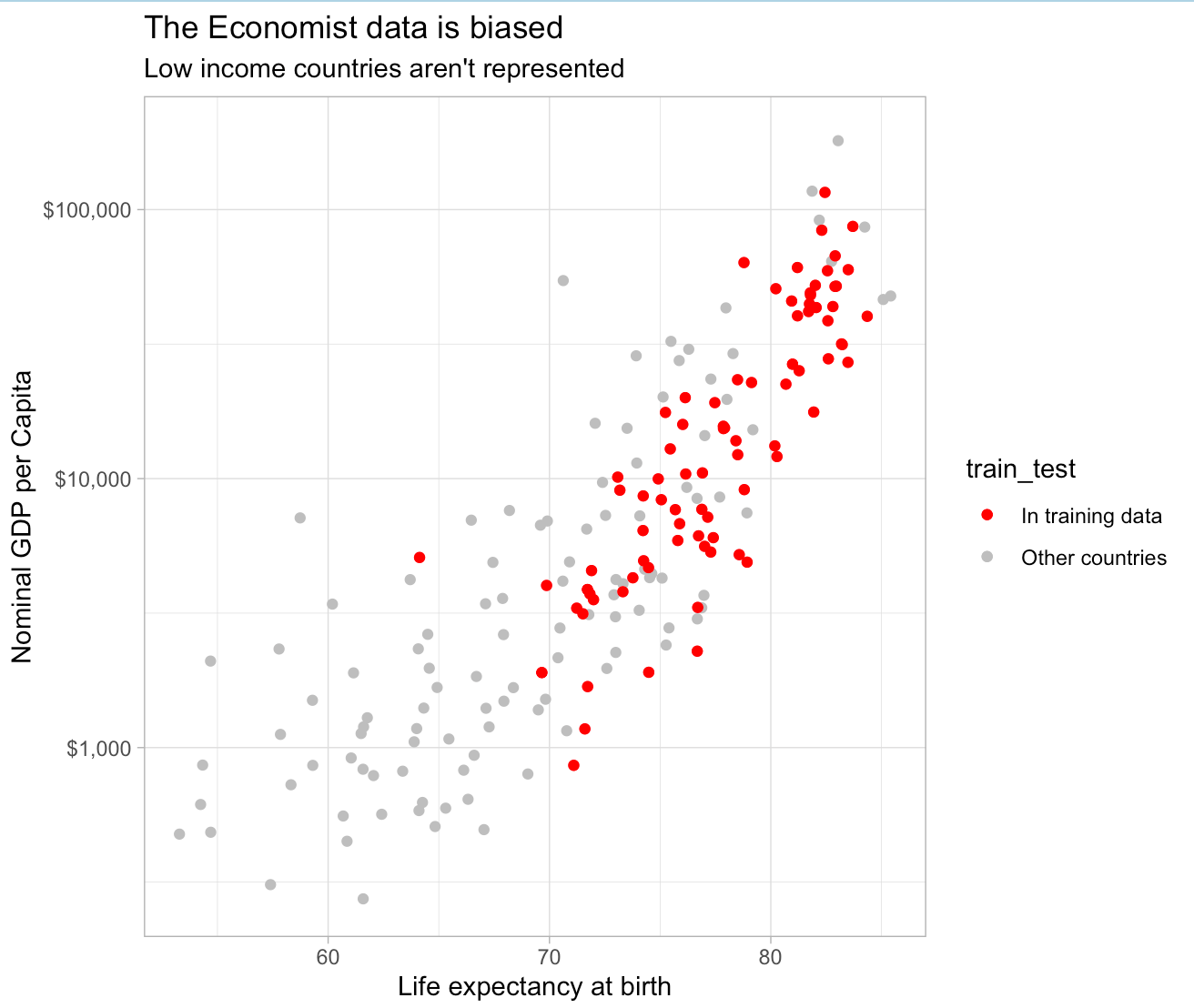
Why the Economist’s excess death model is misleading
Data Science
Covid
The Economist has published a model which estimates that Kenyans are only detecting 4-25% of the true deaths which can be attributed to Covid. I think this is a good…
Sep 7, 2021
Gordon Shotwell
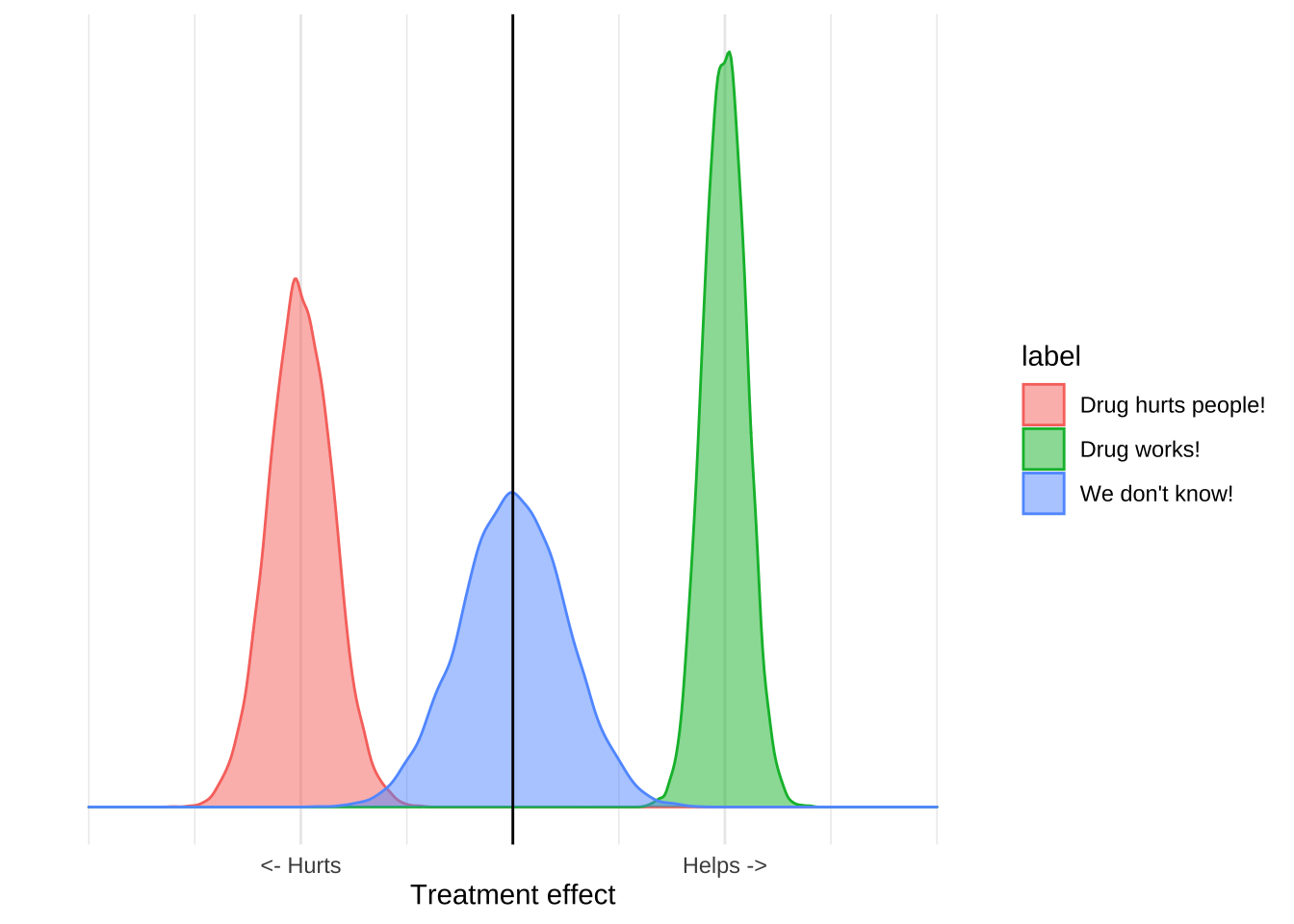
How to make good decisions from bad data
Data Science
Covid
Vitamin D
People often make a categorical distinction between randomized clinical trial data and other forms of data. Under this view the only information that can ground medical…
Nov 21, 2020
Gordon Shotwell
Why I Use R
R
Data Science
Over the last couple of years prominent members of both the R and Python communities have tried to move past the language wars and support both R and Python workflows. This…
Dec 30, 2019
Gordon Shotwell
Technical debt for data scientists
Data Science
Technical debt is the process of avoiding work today by promising to do work tomorrow. A team might identify that there’s a small time window for a particular change to be…
Apr 19, 2019
Gordon Shotwell
“Testing machine learning models with testthat”
Data Science
Automated testing is a huge part of software development. Once a project reaches a certain level of complexity, the only way that it can be maintained is if it has a set of…
May 1, 2018
Gordon Shotwell
“Advice for non-traditional data scientists”
Data Science
Education
I have a pretty strange background for a data scientist. In my career I’ve sold electric razors, worked on credit derivatives during the 2008 financial crash, written market…
Aug 29, 2017
Gordon Shotwell
“R for Excel Users”
Data Science
Education
Like most people, I first learned to work with numbers through an Excel spreadsheet. After graduating with an undergraduate philosophy degree, I somehow convinced a medical…
Feb 2, 2017
Gordon Shotwell
No matching items